AI is Cool - How Do I Use it?
I Have No Idea What I’m Doing
Like practically every developer, I find AI interesting. Like most developers, I have no idea how to write code in such an area. Fortunately, we live in a world where things like Left Pad and is-thirteen actually exist.
If such libraries exist, there must be something in the world of AI…
My quick google search (remember, we’re web developers) has lead me to face-api.js. Neat, we can pull this in with Yarn.
Face-api.js appears to let us:
- Recognise faces
- Determine somebody’s mood
- Find someone’s aparrent gender
Per their docs:

📦 Setup
Now, my setup will be different than yours. The code we’ll execute is React. Wrapped by MDX. Rendered by React. Statically rendered by Gatsby. If I can get this working: you, the reader, are in good shape…
Let’s start by installing the module -
yarn add face-api.js18 seconds. Not bad.
Let’s create a React component - for now this is just an empty component ready for some hooks. We’ll import the module, too:
import React from 'react'
import * as faceapi from 'face-api.js'
export const FaceApiHack = () => {
return (
<div>Hi</div>
)
}Looking at the docs, you need to load a model. There is no idea of a model in their docs… There’s an API call about weights - and a weights folder. Let’s grab that and shove it in static/face-api.
This might kill my Netlify build time, so I might look in to shoving this in an S3 Bucket later on down the line.
Their docs have a section about the different types of models. I’m going to play with “Tiny Face Detector” - this model is pretty performant and appears to be ~190kb. Probably smaller than the image I’m using for this post!
We can create a custom hook to load via their API:
function useTiny() {
const [loaded, setLoaded] = useState(false)
useEffect(() => {
faceapi.nets.tinyFaceDetector
.load('/weights')
.then(() => setLoaded(true))
}, [])
return loaded
}🤖 Detecting our Face
Now, we’ll load our webcam in to a canvas element. This is so we can show what’s actually happening. This should be somewhat straightforward; onload, get the video and update the state. After the state updates, pipe the stream in to the video and paint that on the canvas.
The canvas is important here: I’d like to paint the outputs over it.
useEffect(() => {
if (!stream) {
navigator.mediaDevices
.getUserMedia({video: true})
.then(stream => setStream(stream))
} else {
console.log('oioi')
const {current: vid} = video
const {current: canv} = canvas
vid.srcObject = stream
vid.play()
vid.addEventListener('playing', () => {
const {height, width} = vid.getBoundingClientRect()
canv.height = height
canv.width = width
const ctx = canv.getContext('2d')
function displayFrame() {
if (vid.paused) return
ctx.drawImage(vid, 0, 0, width, height)
requestAnimationFrame(displayFrame)
}
requestAnimationFrame(displayFrame)
})
}
}, [stream])Let’s detect some faces! We can perform a single call to do this:
const opts = new faceapi.TinyFaceDetectorOptions()
const detections = await faceapi.detectSingleFace(canvas.current, opts)Calling this after we’ve painted the canvas, we get the following:
{
"_imageDims": {
"_width": 640,
"_height": 480
},
"_score": 0.6918841745387273,
"_classScore": 0.6918841745387273,
"_className": "",
"_box": {
"_x": 176.5358735275368,
"_y": 196.7644173099547,
"_width": 217.50786175706116,
"_height": 237.74102223202442
}
}🚗 Performance Problems
Now… This is in the displayFrame loop. We lag. This is likely due to my hardware, though I’m rocking a 3rd gen i7.
Let’s break out a separate loop, we don’t need to check every 0.017 second - that’s a little overkill.
Let’s create an interval - every 333ms, we’ll create a detection -
setInterval(async () => {
const opts = new faceapi.TinyFaceDetectorOptions()
const detection = await faceapi.detectSingleFace(canv, opts)
}, 333)This still lags the hell out of the canvas. We can’t do that.
Oddly, the video looks fine! We can just create a fixed element and hopefully overlay that on the video.
There will be some lag, but it’ll look better. Let’s remove the canvas painting code.
At this point, we’ve got a detection. with my debugging efforts, we can see:
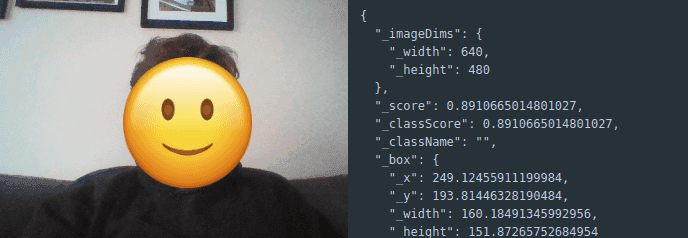
🎨 Drawing on Us
Let’s try to draw an element. Maybe we can cover my face. Let’s create a ref and point it to an element.
Now, we can call getBoundingClientRect() on the video that we’re rendering ourselves in; we’ll add the x/y we get from the detection and move an fixed positioned element over.
Let’s add another hook for this:
useEffect(() => {
if (!curDetection) return;
const {current: fme} = frame
const {current: vid} = video
const {_x, _y} = curDetection._box
const {x, y} = vid.getBoundingClientRect()
fme.style.left = (_x + x) + 'px'
fme.style.top = (_y + y) + 'px'
}, [curDetection])Brilliant, we have a moving box. This is great for showing off that it works.
I’ll plonk a demo below for you to see what’s going on!
Show Video
Enjoy! There’s more that we can do. I won’t write the code here - but I’ll leave some thoughts.
🤔 Thoughts
With less than 100 LoC, we can detect a face, determine it’s gender and infer that face’s mode with a degree of accuracy.
This is a lot of fun for quick hacks - but has huge value for marketing companies and potentially nefarious means.
For the marketing company, one could show a video, somehow get the webcam on and determine the user’s mood - see if they should advertise to the user.
Further in to the Black Mirror world, one could even pause an advert based on attention.
Fortunately, there are some hardcore browser controls that means you need permission from the user before you use their webcam.